
面向谷歌、百度、github、Stackoverflow编程
前言
想了一想,离高考结束也已经一年零几天了。在水校的一年也并没有学到什么,算是又荒废了一年光阴。因此决定建一个博客,督促自己不断学习而非继续碌碌无为。
期末考试大概是5月25日考完的,在家休息了大概一个星期之后,终于来到了实习单位,之前也略闻过计算机行业的办公方式,但亲眼看见却又是另外一种感觉了。实习是从6月4日开始的,到了boss便让我去了解一下人脸识别和神经网络方面的东西,特别指出了Faster R-CNN什么的,当然至今还是云里雾里。
既然老板让我去看,我便花了一个早上去看这是个什么东西。
要了解Faster R-CNN,还是要从图像识别和分类技术发展的祖先一步步来:
CNN→R-CNN→Fast R-CNN→Faster R-CNN
一些神经网络
CNN
CNN(ConvNet/卷积神经网络)是图像识别的初代算法,主要操作有以下几个,若想详细的了解,可以直接拉到最下看参考.
在我这个只了解一下理论暂不实践的半吊子看来主要有以下几步
- 卷积 也就是用不同滤波器对图像进行特征提取

- ReLU ReLU很操作很容易理解 就是把图像里面的每个像素的值范围进行再一次的框定 但是为什么要这么操作我至今也是一知半解
- 池化 我的理解是对上一个卷积层的图像进行Downscale
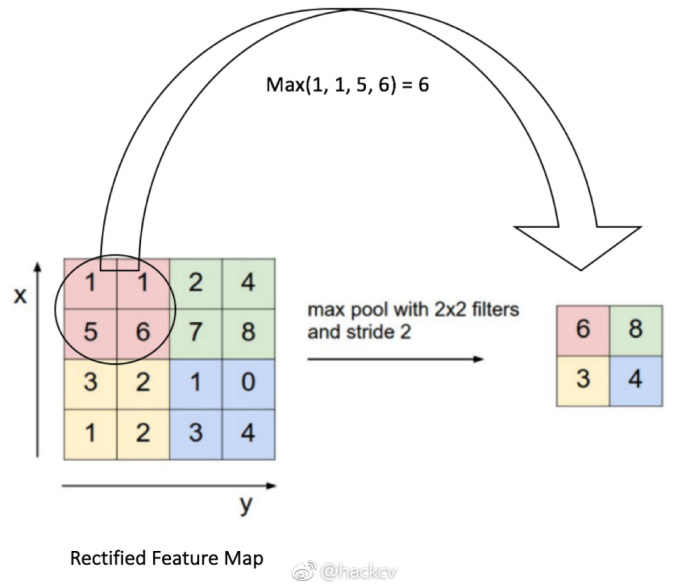
- 全连接层/多层感知器 组合多个层获得神经网络,这块是我最不懂的,至今毫无头绪
- 无尽重复!
R-CNN
R是Regions,从现在开始我们不仅可以知道这图片有啥,更能知道图片里面的东西位置在哪里了。
那么是如何做到的呢?
- 寻找候选框 对图片进行滑动窗口操作获得潜在的正确答案
- CNN 输入CNN神经网络,得到输出
- 分类与边界回归 先得到正确的区域,显然正确答案会有很多种,所以我们需要边界回归,得到最终的精确答案
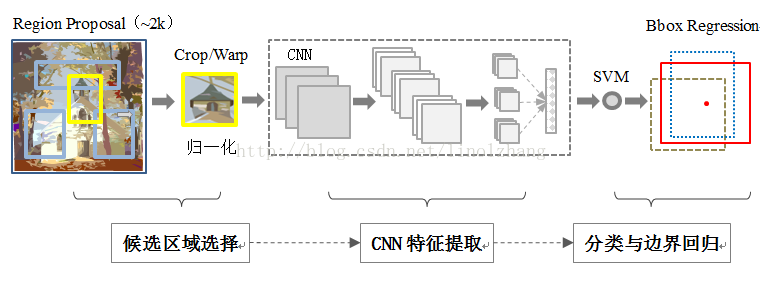
事情很显然了,这样既浪费空间又浪费时间又浪费算力。
Fast R-CNN
其实这之前还有个SSP-Net,优点 1.多尺度输入图像 2.一次CNN,然后再去找正确答案。
然后整合了一些流程,具体的我也并没有非常明白,因为没有用tensorflow实实在在造过这个轮子。
Faster R-CNN
速度的问题其实还是在于选框上,所以干脆把选框也交给CNN,这就是Faster R-CNN了
MTCNN
但是我要做的是人脸检测,目前人脸检测用的最多的还是MTCNN(OpenFace,FaceNet),和前面几个算法对于人脸进行了再次优化,算法流程如下。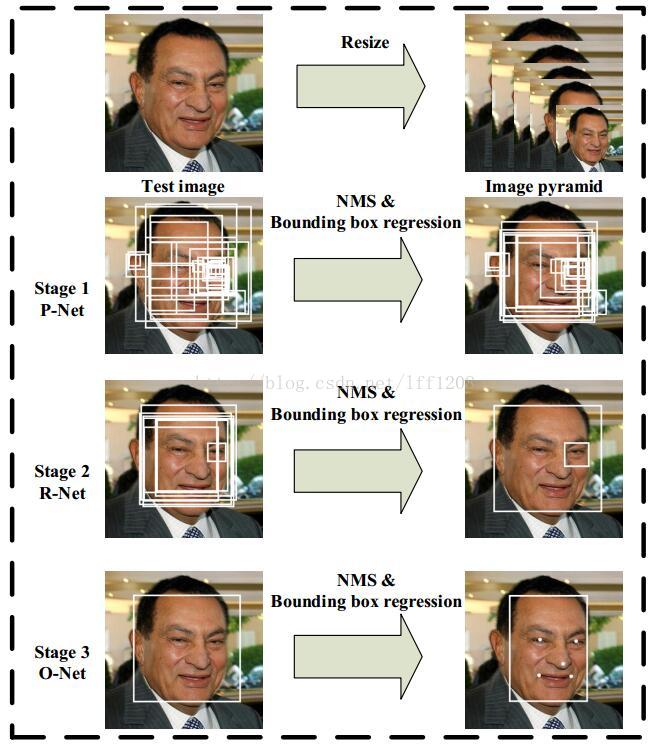
后记
这便是我实习第一天看的东西了。
但是呢理解往往是相对容易的,但操作起来是举步维艰的。
如果是从头造轮子,我的数学以及编程功力都没到位,希望能在两年后的现在有这个能力吧。
因此我决定识别和模型搭建这块先用谷歌开源的FaceNet以及其提供的预处理算法开完成老板给我的任务,老板也表示了同意。
参考文献:
1.见过最好的神经网络CNN解释
2.RCNN介绍
3.基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
4.人脸检测:MTCNN